|
ADO.NET meets XML
Bevor Sie jetzt ein Wiederaufflammen Ihrer XML-Allergie
befürchten und schnell weiterblättern gestatten Sie bitte diesen
Hinweis: In erster Linie geht es im folgenden Beitrag um ADO.NET und erst
in zweiter um XML. Gerade weil dieses Thema in den letzten Jahren bis zum
Abwinken durchgekaut wurde, ist es interessant zu sehen, wie elegant der
.NET Framework XML mit ADO.NET verschmilzt. Diese Diskussion führt
dann auch zum besseren Verständnis der typisierten DataSets.
In den ersten beiden Teilen dieser Einführungsreihe
wurde die DataSet-Komponente und die Funktionsweise von Managed Providern
vorgestellt. Diesmal geht es darum, wie DataSets mit oder ohne Anschluss
an eine Datenbank XML-Dokumente bearbeiten können und wie XML Schema-Definitionen
beim Aufbau von DataSets und Datenbanken benutzt werden. Auch wenn Sie die
letzte Folge [1] verpasst haben sollten, können Sie diesen Beitrag
mit Gewinn lesen, vorausgesetzt, Sie verfügen über die wichtigsten
Grundkenntnisse in ADO.NET und Begriffe wie DataSet und DataTable sagen
Ihnen etwas.
Betrachten wir zur Wiederholung noch einmal kurz die
innere Struktur eines DataSets, wie sie in Bild 1 dargestellt ist. Das DataSet
enthält eine oder mehrere DataTables, die man sich wie Datenbank-Tabellen
oder Ergebnis-Mengen vorstellen kann. Wenn das DataSet mindestens zwei Tabellen
enthält, können zusätzlich Beziehungen zwischen ihnen aufgebaut
werden. Ein Beispiel dafür ist eine Master-Detail Beziehung z.B. zwischen
einer Rechnung und den dazugehörigen Posten. Schließlich gibt
es pro Tabelle auch noch einen oder mehrere DataViews, mit denen festgelegt
wird, welche Zeilen und Spalten der Tabelle zu sehen sind (z.B. in einem
Grid oder in einem Report) und wie diese sortiert werden.
Das ganze spielt sich ausschließlich im Speicher
ab und stellt somit eine vollständige Hauptspeicher-residente-Datenbank
dar. Sie wird mit einem oder mehreren SELECT-Statements über einen
DataAdapter aus einer "echten" Datenbank gefüllt und über
UPDATE, DELETE und INSERT-Anweisungen nach allfälligen Änderungen
mit dieser abgeglichen.
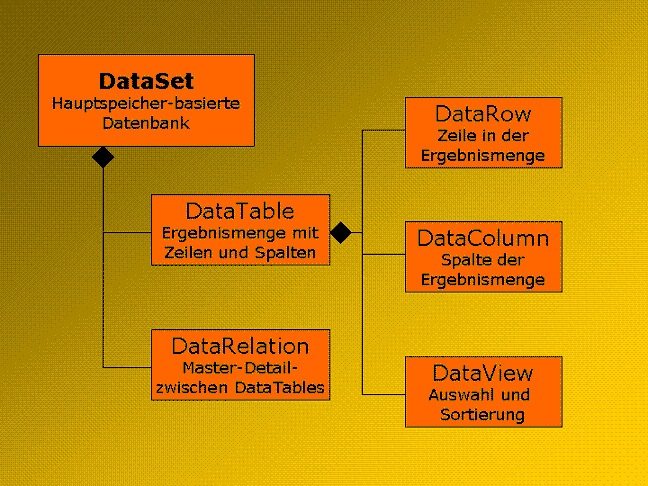
Bild 1: Ein DataSet vereint mehrere Tabellen und
Views in sich und verknüpft diese über Relationen.
Dokumente und Relationen
Soweit das Wesen des DataSets in aller Kürze.
Doch wo kommt hier die Auszeichnungs-Sprache XML ins Spiel? In der letzten
Folge wurde ein Aspekt schon kurz gestreift. Mit den Methoden DataSet.WriteXml
und DataSet.ReadXml, kann das DataSet seinen gesamten Inhalt als
XML -Dokument speichern und auch wieder laden. Das ist auf den ersten Blick
sehr praktisch und vermittelt auf den zweiten einen Aspekt, der einem bisher
vielleicht gar nicht so bewusst war. XML ist eben nicht nur eine Auszeichnungs-Sprache,
mit der Dokumente ähnlich wie in HTML strukturiert werden können,
sondern auch (oder in erster Linie?) eine Form der Datenrepräsentation ähnlich
wie das bekannte CSV-Format und andere.
Im Grunde sind ein XML-Dokument und eine relationale
Datenbank nur zwei verschieden Arten, Informationen in verknüpften
Relationen abzuspeichern und zu verarbeiten. In der XML-Darstellung kann
man diese Informationen auch ohne spezielles Programm z.B. mit einem Texteditor
oder einem Browser ansehen und editieren. Dieses Format eignet sich besonders
auch dazu, Daten zwischen unterschiedlichen Rechnern oder unterschiedlichen
Organisationen auszutauschen. Und schließlich kann ein XML-Dokument
auch recht einfach im Internet verschickt werden, weil es sich um ein Text-Format
handelt, das z.B. über das HTTP-Protokoll Firewalls durchtunneln kann.
Werden die selben Daten in einer relationalen Datenbank
abgelegt, hat das den Vorteil der wesentlich effizienteren Speicherung und
der performanten Verarbeitung. Während in einem XML-Dokument ein Datum
beispielsweise in der Form
<birthday>03/11/1964</birthday>
abgespeichert wird, was in UTF-16 62 Bytes benötigt,
verbraucht das selbe Datum in einer relationalen Datenbank im binären
Format nur 4 Byte. Und natürlich kann eine Datenbank mit Hilfe ihrer
Indexe und den in Jahrzehnten optimierten Algorithmen und ausgetüftelten
Datenstrukturen ein bestimmtes Geburtsdatum aus Millionen in Sekundenbruchteilen
herausfinden, was einem menschlichen Leser, einem XML-Werkzeug aber auch
einem XQuery-Prozessor doch ziemlich schwer fallen dürfte. (XQuery
ist eine Abfragesprache, die - ähnliche wie SQL das für Relationen
tut - aus vorhandenen XML-Dokumenten durch Auswählen, in Beziehung
Setzen und Berechnen neue XML-Dokumente generiert.)
Das DataSet als Vermittler zwischen den Welten
Die Brücke zwischen diesen beiden Arten der Datenspeicherung
stellt das ADO.NET-DataSet dar. Man kann damit ein XML-Dokument laden, bearbeiten
und wieder speichern. Oder man kann eine Abfrage auf eine Datenbank ausführen,
Datensätze editieren, hinzufügen oder löschen und die Änderungen
in die Datenbank zurückschreiben. Man kann aber das Ergebnis der Datenbank-Abfrage
auch einfach als XML-Dokument speichern. Oder ein XML-Dokument laden und
damit eine relationale Datenbank aktualisieren oder gar neu aufbauen. Gerade
die beiden letzten Möglichkeiten sind interessant, weil sie einen nahtlosen Übergang
zwischen den beiden Welten XML und SQL anbieten.

Bild 4: Das ADO.NET-DataSet wirkt wie eine Brücke
zwischen der XML-Welt und der Sphäre der relationalen Datenbanken.
Nehmen wir ein Beispiel aus der Praxis: An einem Firmen-Standort
in der Gemeinde Moos werden LKWs gewogen und die Differenz aus Voll- und
Leergewicht in einer Datenbank erfasst. Aus den Wiege-Ergebnissen jeweils
eines Tages werden Lieferscheine erstellt und zur zentralen Abrechnung an
die Haupt-Geschäftsstelle geschickt. Eine einfache Lösung sieht
so aus: Die Tages-Ergebnisse werden per SELECT aus der Datenbank gefiltert
und als XML-Dokument gespeichert. Das XML-Dokument kann man bequem und preisgünstig
in einer E-Mail verschlüsseln oder über HTTPS uploaden (es müssen
nicht immer Web Services sein!) . In der Haupt-Geschäftsstelle liest
man das XML-Dokument in ein DataSet ein, berechnet auf dieser Speicher-residenten
Datenbank die Lieferscheine und schreibt sie mit einem INSERT in die zentrale
Datenbank.
XML nach relational
Wir gehen etwas vereinfachen davon aus, dass die Wiege-Ergebnisse
im DataSet in Form von zwei Tabellen namens KUNDE und WIEGEN dargestellt
sind. KUNDE enthält die Felder Nummer und Name, WIEGEN die Felder Kunde
für die Kundennummer, Datum und Zuladung. Die beiden Tabellen sind über
eine DataRelation verknüpft, die das Feld KUNDE.Nummer mit dem Feld
WIEGEN.Kunde gleich setzt. Die beiden Tabellen können auf einfache
Weise über zwei DataAdapter und zwei SELECT-Statements aus der Datenbank
in der Filiale Moos gewonnen werden. Nachdem man das DataSet mit WriteXml
abgespeichert hat, erhält man ein XML-Dokument, das in Listing 1 abgebildet
ist.
<?xml version="1.0" standalone="yes" ?>
<tagesbericht-moos>
<wiegen id="765">
<datum>1.1.2002</datum>
<zuladung>34.3</zuladung>
<kunde>
<Nummer>723-2</Nummer>
<Name>Müller Bau</Name>
</kunde>
</wiegen>
<wiegen id="766">
<datum>1.1.2002</datum>
<zuladung>5.3</zuladung>
<kunde>
<Nummer>112-0</Nummer>
<Name>Baustoffe Huber</Name>
</kunde>
</wiegen>
</tagesbericht-moos>
Listing 1: Die Wiege-Daten nach dem Export aus dem DataSet
Man kann an diesem Dokument drei interessante Beobachtungen
machen. Zum einen werden die Inhalte von Tabellen immer in ein komplexes
Element mit dem Namen der Tabelle abgelegt. Zweitens sind die Daten als
ungeparster Text gespeichert. Möglich wäre es auch, die Daten
als Attribute abzulegen und das DataSet unterstützt diese Variante
auch. Allerdings ist normaler Text die Standard-Einstellung. Und schließlich
spiegelt sich die Master-Detail-Beziehung der Tabellen in einem hierarchisch
verschachtelten Dokument wieder. Auf alle diese Aspekte werden wir im Folgenden
noch näher eingehen, doch zuerst verfolgen wir den weiteren Weg des
Dokuments.
Die Tages-Ergebnisse haben soeben ihre erste Metamorphose
von SQL nach XML hinter sich gebracht und können nun sehr einfach weiterverarbeitet
werden. Wenn das Dokument nicht zu umfangreich ist, kann es mit ein bisschen
Erfahrung von einem Mitarbeiter in einem Text-Editor auf Plausibilität überprüft
werden. Fehlt ein Kunde oder ist die Zuladung eines LKWs negativ? Solche
Prüfungen sind natürlich schon beim Erfassen in der Datenbank
gelaufen. Trotzdem geht nichts über menschliche Kontrolle und auf jeden
Fall hat der Anwender das gute Gefühl, die Arbeit des Systems zu durchschauen.
Es gibt eine ganze Reihe von Möglichkeiten, das
XML-Dokument in die Zentrale zu schicken. E-Mail ist nur eine davon und
erlaubt keine vollständige Automatisierung. Trotzdem profitiert man
auch hier davon, dass die Daten nun als reiner Text vorliegen. Der Firewall
in der Haupt-Geschäftsstelle kommt so gar nicht erst auf die Idee,
dass hier irgendetwas Gefährliches übertragen wird und wird unseren "Text"
deshalb unverändert und sofort weiterleiten.
Relational nach XML
In der Zentrale kann man das Dokument direkt in ein
DataSet einlesen und weiterverarbeiten. Die daraus gewonnenen Lieferscheine
legt man in einem zweiten DataSet an und schreibt sie wie gewohnt in die
zentrale Datenbank. Der interessante Punkt ist hier das Einlesen des XML-Dokuments.
Denn trotz aller Gemeinsamkeiten zwischen XML und relationalen Tabellen
ist die Abbildung eines XML-Dokumentes auf ein DataSet nicht ganz so einfach
wie der umgekehrte Weg. XML erlaubt eben nicht nur strenge tabellarische
Daten sondern beliebige Dokumente, die in einer Tabelle gar nicht dargestellt
werden können wie das folgende einfache Beispiel zeigt:
<buch>
Der <genre>Roman</genre> von <autor>H. J. Rubenfels</autor>
kam im Jahr <erscheinungsdatum>1967</erscheinungsdatum> bei <verlag>Kernbach</verlag> heraus.
</buch>
Solange das XML-Dokument aber eine relationale Struktur
hat, ist das DataSet durchaus in der Lage, diese zu bestimmen und die Daten
korrekt auf Tabellen aufzuteilen. Dies macht es in drei Schritten. Im ersten
wird aus dem XML-Dokument ein XML-Schema gewonnen, im zweiten aus dem XML-Schema
eine relationale Datenbankstruktur erzeugt und die entsprechenden Tabellen
im DataSet angelegt und im dritten die Daten aus dem Dokument in das DataSet
importiert.
Dies alles geschieht innerhalb der Methode DataSet.ReadXml.
Man kann die einzelnen Teilschritte aber auch selbst in der Entwicklungsumgebung
nachvollziehen. Dazu fügt man die XML-Datei mit Datei/Vorhandenes
Element hinzufügen... dem Projekt hinzu, öffnet sie und synchronisiert
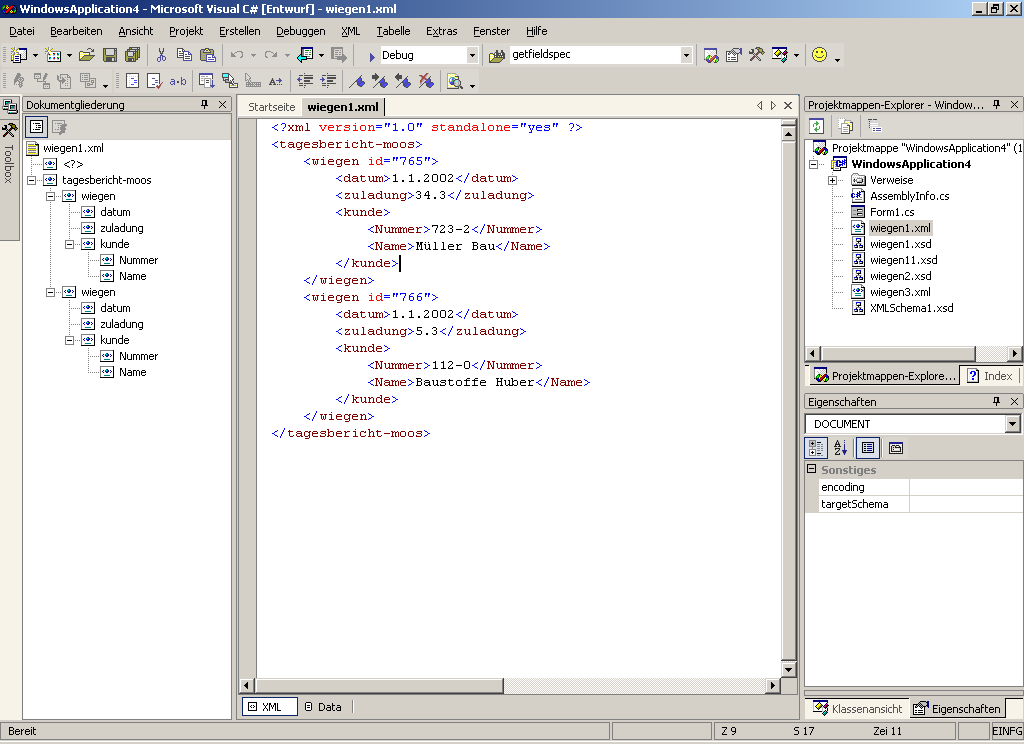
dann die Dokumentengliederung im lokalen Menü. Das Ergebnis ist in
Bild 2 zu sehen. Aus dieser Sicht heraus können Sie die Daten direkt
bearbeiten oder ein XML-Schema und ein typisiertes DataSet erstellen lassen.
Das Editieren der Daten kann wiederum entweder direkt im XML-Quellcode geschehen
oder über ein Daten-Gitter.
Screenshot: Dokumentengliederung
und XML-Sicht der Wiege-Datei. Das Daten-Gitter verbirgt sich hinter dem
Reiter für die Data-Ansicht.
Die Freude über diese einfache Konvertierung
währt allerdings nicht lange. Denn bald stellt man fest, dass bei der
automatischen Generierung des Schemas und damit auch des DataSets die Datentypen
verlorengegangen sind. Alle Felder werden als string ausgeführt,
was nun wirklich nicht beabsichtigt war. Andererseits, wie soll Visual Studio
auch die Absicht erraten, die hinter der Zeichenkette "34.4" steckt?
Dokumente mit Struktur
An dieser Stelle kommt das Thema XML-Schema ins Spiel.
Eine XML-Schema-Definition ist eine Beschreibung, die festlegt, was in einem
bestimmten XML-Dokument stehen darf und was nicht. Insbesondere definiert
ein Schema, welche Elementnamen im Dokument vorkommen dürfen, welche
Daten und Attribute zu einem Element gehören und wie diese Elemente
angeordnet werden. Wer nun an DTDs denkt, liegt durchaus richtig. Allerdings
wurden die Dokumenten-Typ-Definitionen im letzten Jahr ganz offiziell von
XML-Schemas abgelöst. (Es handelt sich also um einen Standard des World
Wide Web Consortiums und nicht um eine Erfindung von MS.) Diese haben der
Vorteil, dass sie zum einen eine durchgängigere Struktur aufweisen
und zum anderen auch selbst wieder in XML verfasst sind. Dadurch kann man
XML-Schemas mit den selben Werkzeugen bearbeiten wie die Dokumente. Darüber
hinaus spricht für XML-Schemas, dass sie "alle" Datentypen
wie Ganzzahlen, Fließkommazahlen, Datumsangaben usw. kennen, während
in DTDs nur Zeichenketten vorkommen können.
Wenn Sie bisher weder Dokument-Typ-Definitionen noch
Schemas verwendet haben, fragen Sie sich vielleicht wozu so etwas gut ist?
Genügt es nicht ein XML-Dokument mit allen Daten zu haben? Für
eine CSV-Datei, die ja schließlich so etwas wie der Vorgänger
von XML ist, war doch auch keine zusätzliche Definition nötig?
Eben doch! Es gibt zwar keine formalisierte Beschreibung für eine CSV-Datei,
sie wäre aber in vielen Fällen nützlich, um herauszufinden,
was die einzelnen Spalten bedeuten und welche Datentypen und Datenbereich
jeweils erlaubt sind. Und weil XML doch um einiges komplexer ist als CSV,
ist eine solche Beschreibung noch nötiger als dort. Ein XML-Schema
beantwortet Fragen wie (bezogen auf das Wiegen-Beispiel):
- Darf es auch Einträge ohne Kunden-Angabe
geben?
- Sind Wiege-Ergebnisse immer positiv oder dürfen
sie auch negativ sein?
- Sind die Resultate nur ganze Zahlen oder mit
Angaben mit Nachkomma-Stellen?
Das sind ganz offensichtlich Fragen, die jeder beantworten
muss, der ein solches Dokument erstellt oder verarbeitet. Die XML-Schema-Definition
legt solche und ähnliche Vorgaben ganz präzise fest, so das man
nicht auf eine umgangssprachliche Beschreibung angewiesen ist. Außerdem
ist es mit einem XML-Schema möglich, ein Dokument vollautomatisch daraufhin
zu überprüfen, ob es den Regeln entspricht oder nicht.
Ein konkretes Schema
Eine Möglichkeit, wie ein Schema für das
obige XML-Dokument aussehen könnte ist in Listing 2 dargestellt. Dies
ist nur eine mögliche Variante von vielen. Ähnlich wie bei einer
Programmiersprache gibt es auch in XML-Schemas meist mehrere unterschiedliche
Wege, dasselbe zu erreichen. Je nach Aufgabenstellung, Projektgröße
und persönlichem Geschmack des Autors sieht das Schema dann etwas anders
aus. Die hier vorgestellte Variante ist aber diejenige, die auch in Visual
Studio eingesetzt wird.
<xsd:schema id="tagesbericht-moos" targetNamespace="http://tempuri.org/wiegen.xsd"
xmlns="http://tempuri.org/wiegen1.xsd" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="tagesbericht-moos">
<xsd:complexType>
<xsd:choice maxOccurs="unbounded">
<xsd:element name="wiegen">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="datum" type="xsd:date" minOccurs="1" />
<xsd:element name="zuladung" type="xsd:float" minOccurs="1" />
<xsd:element name="kunde" minOccurs="1" maxOccurs="1">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="Numme r"type="xsd:string" minOccurs="1" />
<xsd:element name="Name" type="xsd:string" minOccurs="1" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:int" />
</xsd:complexType>
</xsd:element>
</xsd:choice>
</xsd:complexType>
<xsd:unique>
<xsd:selector xpath=".//wiegen" />
<xsd:field xpath="@id" />
</xsd:unique>
</xsd:element>
</xsd:schema>
Listing 2: Ein mögliches XML-Schema
für das Wiegen-Dokument, in dem die Master-Detail-Beziehung durch Verschachtelung
ausgedrückt wird .
Nach dem üblichen XML-Kopf und dem Hinweis auf
das XML-Schema (ein XML-Schema ist wie gesagt ein normales XML-Dokument
und wird deshalb wiederum durch ein Schema beschrieben.) folgt die Definition
des einzigen Elements auf der obersten Stufe: tagesbericht-moos.
Der Tagesbericht ist ein komplexer Typ, was bedeutet, dass er Attribute
und/oder untergeordnete Elemente enthalten kann. In diesem Fall sind die
untergeordneten Elemente die einzelnen Wiegungen, von denen es pro Tag unbeschränkt
viele geben kann. Darauf weist der Attribut-Wert unbounded beim
Element choice hin. Das Element choice spezifiziert eine Auswahl
aus den untergeordneten Elementen, hat in diesem einfachen Schema aber keine
echte Funktion, da es nur ein untergeordnetes Element gibt, eben wiegen.
Dieses wiederum besteht aus Datum, Zuladung und Kunde.
Die ersten beiden in dieser Liste sind einfache Datentypen und enthalten
nichts anderes als ihren Wert. Der Kunde dagegen enthält die untergeordneten
Elemente Nummer und Name, die wegen des sequence-Elements immer in dieser
Abfolge aufgeführt werden müssen. Jedes dieser Elemente muss vorhanden
sein, was durch das Attribut minOccurs = "1" festgelegt
wird. Beim Kunden definiert das Attribut maxOccurs = "1"
darüber hinaus noch, dass mehr als ein Kunde pro Wiegung nicht erlaubt
ist. Es muss also genau einen Kunden für jedes wiegen-Element
geben.
Die Identifikation der Wiegung ist als Attribut realisiert
und wird hinter der Sequenz der untergeordneten Element spezifiziert. Als
Datentyp benutzen wir eine ganze Zahl. Diese darf im gesamten Dokument nicht
doppelt vorkommen. Daher enthält der tagesbericht-moos noch
ein unique-Element, das mit dem Pfad auf das untergeordnete wiegen zeigt
und dessen Attribut id als eindeutig spezifiziert.
Schlüssel und Referenzen
Dieses Beispiel liefert natürlich nur einen kleinen
Einblick in die XML-Schema-Sprache, enthält aber fast schon alles,
was für den Anwendungsbereich ADO.NET wichtig ist. Zwei spezielle Element
müssen allerdings noch erklärt werden. Sie hängen damit zusammen,
dass man das Beispiel-Dokument auch erheblich platzsparender formulieren
könnte. In seiner aktuellen Form führt es einen Kunden in der
immer gleichen Kombination aus Nummer und Name sooft auf, wie dieser Kunde
mit einem LKW auf der Waage gestanden hat. Diese Daten könnte man effizienter
in zwei Listen organisieren, die einerseits die Wiege-Vorgänge beinhalten
sowie andererseits die Kunden-Daten und über das Element-Paar nummer
und kunde verknüpft sind.
Ein Schema für diese Datenstruktur ist in Listing
3 zu sehen. Die Elemente wiegen und kunde sind nun nicht mehr verschachtelt
sondern stehen gleichberechtigt im choice-Element. Dadurch kann das Dokument
beliebig viele einzelne wiegen- und kunde-Elemente in beliebiger Reihenfolge
enthalten. Mit dem key-Element wird die Kundennummer innerhalb von wiegen
als Schlüssel identifiziert und mit dem keyref-Element stellt das Schema
die Beziehung zum Wiege-Eintrage dar. Ein Dokument gemäß diesem
Schema könnte aussehen wie in Listing 4, aber auch wie das ursprüngliche
aus Listing 1.
<?xml version="1.0" encoding="utf-8" ?>
<xsd:schema id="Dataset1" targetNamespace="http://tempuri.org/wiegen2.xsd"
xmlns="http://tempuri.org/wiegen2.xsd" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="tagesbericht-moos">
<xsd:complexType>
<xsd:choice maxOccurs="unbounded">
<xsd:element name="wiegen">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="datum" type="xsd:date" minOccurs="1" />
<xsd:element name="zuladung" type="xsd:float" minOccurs="1" />
<xsd:element name="kunde" type="xsd:int" minOccurs="1" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="kunde">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="name" type="xsd:string" minOccurs="1" />
<xsd:element name="nummer" type="xsd:int" minOccurs="1" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:choice>
</xsd:complexType>
<xsd:keyref name="kundewiegen" refer="kundenschluessel">
<xsd:selector xpath=".//wiegen" />
<xsd:field xpath="kunde" />
</xsd:keyref>
<xsd:key name="kundenschluessel">
<xsd:selector xpath=".//kunde" />
<xsd:field xpath="nummer" />
</xsd:key>
</xsd:element>
</xsd:schema>
Listing 3: Ein alternatives XML-Schema für
das Wiegen-Dokument unter Verwendung der key- und keyref-Elemente
Obwohl in diesen Absätzen eigentlich von XML
und XML-Schemas die Rede war, ist Ihnen sicherlich aufgefallen, dass die
Denkweise genauso gut auf ein relationales Datenbank-Schema übertragbar
ist. Auch hier geht es um Listen (=Tabellen) von Elementen (=Datensätzen)
mit typisierten Feldern, um Eindeutigkeit, Schlüssel und Beziehungen
zwischen Datensätzen in unterschiedlichen Tabellen. Der Übergang
von der ersten Schema-Definition zur zweiten, effizienteren war in Datenbank-Sprache
ausgedrückt eine Normalisierung.
Es ist also möglich XML-Schemas mit Datenbank-Schemas
zu identifizieren, so wie XML-Dokumente auch Datenbanken entsprechen. Dabei
sollte man sich allerdings bewusst sein, dass XML wesentlich ausdrucksstärker
ist als die Sprache der Datenbank-Tabellen und somit zwar jede Datenbank
als XML-Dokument abgespeichert werden kann aber nicht jedes XML-Dokument
als Datenbank.
Typisierte DataSets
Visual Studio und der .NET-Framework benutzen XML-Schemas,
um die Struktur von DataSets zu definieren und damit nicht nur den Aufbau
von XML-Dokumenten sondern auch die entsprechenden Datenbank-Schemas. Ein
DataSet, dem schon zur Entwurfszeit ein XML-Schema zugeordnet ist, wird
typisiertes DataSet genannt. Seine Tabellen, Spalten und Constraints sind
in der Entwicklungsumgebung bekannt. Deshalb kann der Komponenten-Designer
eine typsichere von DataSet abgeleitete Klasse erstellen, deren Tabellen
und Spaltennamen den Namen in der Datenquelle (Datenbank oder XML-Dokument)
entsprechen. Typsicher ist diese Ableitung deshalb, weil die Feldwerte nicht
mehr als Object gelesen und geschrieben werden, sondern nur noch mit dem
korrekten Datentyp.
Es gibt mehrere Wege, um ein typisiertes DataSet zu
erzeugen:
- Einen oder mehrere DataAdapter in das Projekt
einfügen und das typisierte DataSet vom Komponenten-Designer erzeugen
lassen
- Ein neues DataSet anlegen und eine vorhandene
Datenbank-Struktur von einem erreichbaren Rechner übernehmen
- Ein XML-Schema manuell erstellen und daraus ein
typisiertes DataSet generieren lassen
Die erste Variante wurde in der vorherigen Folge dieser
Einführungsreihe schon beschrieben. Es ist wohl die am häufigsten
benutzte und außerdem diejenige, bei der man mit der zugrundeliegenden
XML-Technologie nicht in Berührung kommt (außer man wirft einen
Blick auf die Festplatte und entdeckt die zugehörige .xsd-Datei.)
Die beiden anderen Varianten basieren auf dem XML
Schema Designer, einem graphischen Werkzeug zum Erstellen und Bearbeiten
von XML-Schemas. Um die Arbeit mit diesem Tool zu demonstrieren, entwerfen
wir ein DataSet für das Beispiel-Projekt. Nachdem eine neue Windows-Anwendung
erzeugt wurde, fügen Sie mit Datei/Neues Element hinzufügen...
ein XML-Schema ein. Sie sehen nun die noch leere Arbeitsfläche des
XML Schema Designers, welcher die beiden Sichten Schema und XML anbietet.
Die Schema-Sicht ist eine graphische Darstellung der Dokumenten-Struktur,
die nicht ganz zufällig wie ein Entity-Relationship-Diagramm aussieht.
Die XML-Sicht zeigt das XML-Schema im XML Quelltext.
Bild
3: Der XML Schema Designer kann eine Art Entity-Relationsship-Diagramm für
das Schema darstellen.
Der XML-Schema-Designer
Solange der XML Schema Designer aktiv ist, enthält
der Werkzeugkasten statt der Komponenten XML-Schema-Tags wie element,
attribute, complexType und key. Um die zweite
Variante des Beispiels, also diejenige mit zwei getrennten Listen für
Wiegung und Kunde, zu implementieren, benötigt man die übergeordnete
Gruppe sowie zwei Elemente. Diese werden wie auch bei Komponenten üblich
aus dem Werkzeugkasten auf die Arbeitsfläche gezogen. Im Kopf trägt
man den Namen des Elements ein und in die Zeilen darunter die dazugehörigen
untergeordneten Elemente und Attribute. In unserem Beispiel sind alle untergeordneten
Felder mit Ausnahme des Schlüssels Elemente, während die Wiege-Id
als Attribut realisiert wird.
Für letzteres benötigen wir auch ein
key-Element. Dazu zieht man dieses aus dem Werkzeugkasten auf das entsprechende übergeordnete
Element und gibt einen Namen für den Schlüssel, das übergeordnete
Element und das oder die Schlüsselfeld(er) an.
Zu guter Letzt wird die Beziehung zwischen den beiden
Elementen hergestellt, indem man eine Relation auf das Element wiegen zieht.
Die Eigenschaften einer Relation entsprechen denen einer referentiellen
Integrität oder Master-Detail-Beziehung. Dazu kommt eigentlich nur,
dass man auch für die Relation selbst einen Namen vergeben muss. Für
die DataSet-Eigenschaften im unteren Teil dieses Dialogfeldes, also für
die Fremdschlüssel-Einschränkung und die diversen Aktualisierungs-Regeln
gibt es wie übrigens auch für die Eigenschaft Primärschlüssel
beim key-Element keine Entsprechung im Standard für XML-Schema-Definitionen.
Wer hier von den Vorgaben abweicht, erhält Microsoft-spezifische XML-Schema-Erweiterungen
in der .xsd-Datei, die am Namensraum msdata zu erkennen sind. Dies
Erweiterungen stammen zwar von Microsoft, halten sich aber an den standardisierten
Erweiterungs-Mechanismus für XML-Schema-Definitionen.
Das Resultat dieser Bemühungen kann man sehen,
wenn die Ansicht auf XML umgeschaltet wird. Es entspricht im Wesentlichen
den Erwartungen, d.h. dem Dokument aus Listing 3. Allerdings fehlt noch
das unique-Element und die korrekten Werte für minOccurs
und maxOccurs, weil diese im graphischen Editor nicht zur Verfügung
stehen. Sie können jedoch problemlos im XML-Editor nachträglich
eingegeben werden. Alternativ verwendet man statt unique ebenfalls
key, wodurch zusätzlich erzwungen wird, dass immer ein gültiger
Wert im Attribut steht.
Ein typisiertes DataSet erzeugen
Damit steht das XML- bzw. Datenbank-Schema und kann
als Basis für das DataSet der Anwendung verwendet werden. Der Menüpunkt
Schema/DataSet generieren..., der nur in der Schema-Ansicht verfügbar
ist, bewirkt, dass bei jedem Speichern der .xsd-Datei der Quellcode für
das typisierte DataSet in der Programmiersprache des Projekts neu erzeugt
wird. Sobald Sie diesen Menüpunkt aktiviert haben, finden Sie im Verzeichnis
der Anwendung eine Datei XMLSchema1.cs mit dem C#-Quellcode für das
DataSet (XMLSchema1.vb, wenn Sie mit Visual Basic arbeiten).
Im Projektmappen-Explorer ist sie unter dem Knoten
der Schema-Datei eingeordnet, wenn Sie die Option Alle Dateien anzeigen
aktiviert haben. Der Quellcode sieht im Prinzip genau so aus wie beim "handgemachten"
typisierten DataSet in der vorherigen Folge. Um es in die Anwendung aufzunehmen,
muss man nur noch eine Instanz erzeugen und beispielsweise mit einem Daten-Gitter
verbinden (Listing 5).
private DataSet dataSet1;
public MyForm()
{
InitializeComponent();
// Generiertes typisiertes DataSet erzeugen…
this.dataSet1 = new _tagesbericht_moos();
// …und verknüpfen
dataGrid1.DataSource = dataSet1;
}
Listing 5: Ein vom XML Schema Designer generiertes typisiertes DataSet wird instanziiert und mit einem Daten-Gitter verbunden.
In vielen Fällen baut man aber die Struktur des
DataSet nicht neu auf, sondern möchte eine vorhandene Struktur übernehmen.
Dafür bietet das Visual Studio eine ganze Reihe von Möglichkeiten:
- Sie können ein vorhandenes XML-Schema dem
Projekt hinzufügen und daraus ein DataSet generieren lassen
- Tabellen, Stored Procedures oder Views können
aus bestehenden Datenverbindungen des Server-Explorers auf die Arbeitsfläche
des XML Schema-Designers gezogen werden.
- Auch beim Generieren eines typisierten DataSets
aus einem DataAdapter wird ein XML-Schema erstellt.
- Aus einem XML-Dokument wird direkt ein passendes
XML-Schema erstellt.
Die letzte dieser Alternativen haben wir wegen diverser
Schwächen weiter oben schon als Realisierungsmöglichkeit für
das Einlesen der Wiege-Daten ausgeschlossen. Trotzdem ist die Vorgehensweise äußerst
interessant und für Prototypen eine geniale Sache. Deshalb sehen wir
uns den dahinter stehenden Algorithmus noch etwas genauer an.
Das Schema erschließen
Das Berechnen des XML-Schemas aus dem XML-Dokument
wird Inferenz genannt. Bei der Betrachtung gehen wir von dem XML-Dokument
des Wiege-Beispiels aus (Listing 3). Hier sind die Regeln:
- Als erstes wird entschieden, ob das Dokument selbst als DataSet
oder als Tabelle abgebildet wird. Wenn es weder Attribute noch einfache
untergeordnete Elemente hat, wird das Dokument zum DataSet ansonsten
zu einer Tabelle. Im zweiten Fall wird das umschließende DataSet
mit dem Namen NewDataSet automatisch generiert.
- Alle Elemente mit komplexem Inhalt, also mit Attributen oder untergeordneten
Elementen werden auf Tabellen abgebildet.
- Alle Elemente, die beliebig oft vorkommen dürfen, werden ebenfalls
zu Tabellen.
- Attribute und einfache untergeordnete Elemente werden zu Spalten
mit dem Namen und Datentyp des Attributs bzw. Elements.
- Da komplexe untergeordnete Elemente nach diesen Regeln nur in eigenen
Tabellen abgespeichert werden können, muss für sie eine Master-Detail-Beziehung
aufgebaut werden. Dazu werden beide Tabelle mit einem zusätzlichen
Schlüssel versehen und eine entsprechende Relation erzeugt.
- Elemente mit Attributen oder wiederholte Elemente werden nach diesen
Regeln als Tabelle modelliert. Wenn sie nur einfachen Text enthalten,
legt der Inferenz-Prozess für diesen Text eine spezielle Spalte
an. Die entstehende Tabelle ist dann einspaltig. Sind im Text allerdings
weitere untergeordnete Element enthalten, werden die Elemente zu Spalten
und der Text wird ignoriert.
In Regel 6 steckt eine weitere große Einschränkung
des Inferenz-Mechanismus. Alle Memo-artigen XML-Dokumente mit in Text eingebetteten
Elementen (wie die oben erwähnte Buch-Beschreibung) können nicht
auf die relationale Struktur abgebildet werden. Wenn man es doch versucht,
gehen Informationen verloren.
Einschränkungen der Inferenz
Ansonsten funktioniert es allerdings recht gut, wie
man anhand er Wiege-Daten feststellen kann. Nach Regel 1 wird die Wurzel
des Dokuments auf ein DataSet abgebildet, das nach Regel 2 zwei Tabellen
namens WIEGEN und KUNDE enthält. Die Spalten dieser Tabellen setzen
sich nach Regel 4 aus den Attributen und den untergeordneten einfachen Elementen
zusammen. Das key- und keyref-Element zusammen bilden
eine Fremdschlüssel-Relation, welche die Zuordnung der Wiegung zum
Kunden beschreibt. Sogar wenn wir die verschachtelte Variante aus Listing
1 als Ausgangspunkt benutzt hätten, würde Regel 5 dafür sorgen,
dass das gleiche XML-Schema dabei herauskommt.
In Regel 4 ist das Problem der Datentypen enthalten,
wird aber verschwiegen Hier heißt es lapidar, dass die Spalten der
Tabelle den Datentyp des Attributs bzw. Elements erhält. Den präzisen
Datentyp erfährt man aber nur aus einer XML-Schema-Datei. Verfügt
man nur über das XML-Dokument selbst, muss man raten: Ist der Text
100 ein string, ein Integer, ein Byte oder ein Float? Ist 18.07.01 ein string
(z.B. für eine Bestellnummer) oder ein Datum? In dieser Not bildet
Visual Studio alle Daten auf strings ab.
Auch Regel 3 hat ihre Tücken. Die folgenden beiden
XML-Dokumente unterscheiden sich eigentlich nur dadurch, dass das eine zwei
Kunden enthält während das andere nur einen Kunden beschreibt:
<kunden>
<kunde>Mager GmbH</kunde>
<kunde>Hans Fett & Söhne</kunde>
</kunden>
<kunden>
<kunde>Dünnbier AG</kunde>
</kunden>
Regel 3 sorgt hier dafür, dass im ersten Fall
aus kunde eine Tabelle und somit aus kunden ein DataSet
wird. Im zweiten Fall greift diese Regel allerdings nicht, weshalb die Inferenz
zu einer Tabelle KUNDEN mit einer Spalte kunde führt. Das
ist sicher nicht erwünscht und wird mit hoher Wahrscheinlichkeit in
der verarbeitenden Anwendung einen Fehler auslösen. (Wer testet schon
Dokumente mit einem einzigen Eintrag?)
Die Inferenz einer relationalen Struktur aus einem
XML-Dokument ist also eine wirklich praktische Angelegenheit, die erstaunlich
gut aber eben nicht perfekt funktioniert. Sie kommt berechtigterweise vor
allem während der Entwicklungsphase und in Prototypen zum Einsatz,
taugt aber in den allermeisten Fällen nicht für den Produktions-Betrieb.
Deshalb die Empfehlung: Arbeiten Sie wo es geht mit typisierten DataSets
und geben Sie ihren XML-Dokumenten immer ein XML-Schema mit. Ein Zusatzaufwand
entsteht dadurch kaum, weil das Schema ja sowieso von Visual Studio erzeugt
wird.
Fazit
Damit kommt diese Artikelserie über ADO.NET zu
ihrem Abschluss. Glücklicherweise ist nicht nur vieles anders geworden
sondern auch einiges besser. Die Entwickler müssen wieder einmal um-
bzw. dazulernen und werden dafür unter anderem mit der erstklassigen
XML-Integration belohnt. In anderen Punkten wie der ausschließlichen
Konzentration auf unverbundene DataSets bleibt abzuwarten, ob uns die nächste
Version von ADO.NET nicht doch noch etwas entgegenkommen wird.
Peter Pohmann ist Geschäftsführer von
dataweb, einem Softwarehaus in Niederbayern. Er ist seit über 15 Jahren
als Entwickler, Fachautor, Coach, Referent und Berater für Objektorientierte
Technologien und Windows-Programmierung tätig. Er freut sich über
Feedback zu diesem und verwandten Themen an peterDOTpohmannADDdataweb.de
|


{kind=link}