Das ADO.NET DataSet
Die herausragende Neuerung in ADO.NET ist die radikale
Beschränkung auf unverbundene Datenmengen und damit auch der fast vollständige
Verzicht auf Server-seitige Cursors. Im Mittelpunkt dieser Denkweise steht
die neu konzeptionierte DataSet-Komponente, die im Grunde eine komplette
Speicher-residente Datenbank darstellt. Der folgende Artikel erklärt
den Umgang mit DataSets, die Aktualiserung von DataSet-Inhalten gegen eine
Datenquelle und die Funktionsweise von Daten-gebundenen Steuerelementen.
Dieser Beitrag ist die zweite Folge einer dreiteiligen
Einführungsreihe in ADO.NET. Auch wenn Sie den ersten Teil [1] verpasst
haben, der sich mit den Komponenten eines Managed Providers, also Connection,
Command, DataReader und DataAdapter beschäftigte, können Sie noch
problemlos einsteigen. Dieser Teil ist weitgehend unabhängig vom ersten,
und wo es nötig ist, werden die zentralen Begriffe noch einmal kurz
erklärt. Dazu gehört in der Hauptsache das Konzept der unverbundenen
Datenmenge (disconnected data set). Es besagt, dass das Ergebnis einer Datenbank-Abfrage
keine Verbindung zur Datenbank aufrecht erhält, während es bearbeitet
wird. Eine Datenbankverbindung wird erst dann wieder benötigt, wenn
die Änderungen - meist mehrere auf einmal - zurückgeschrieben
werden. Nach dem Ausführen des SELECT-Befehls und dem Abholen der Ergebnismenge
wird deshalb die Verbindung zur Datenbank geschlossen und erst wieder geöffnet,
wenn eine Aktualisierung oder eine neue Abfrage ausgeführt wird.
Ein mächtiger Daten-Cache
Warum geht man so vor? Der Hauptgrund liegt in der
Skalierbarkeit der Anwendung. Solange die Datenbankverbindung geöffnet
ist, muss die Datenquelle (z.B. SQL Server oder die Jet Engine) teilweise
umfangreiche Verwaltungsinformationen bereit halten. Dazu gehören Verbindungsdaten
wie z.B. die Rechte des Benutzers, laufende Transaktionen und Zwischentabellen
für die Cursor-Engine. Die maximale Anzahl gleichzeitig offener Verbindung
ist dadurch beschränkt und liegt je nach Hardware und Beanspruchung
in der Größenordnung von 100. Wird die Bearbeitung der Daten
jedoch ausschließlich offline durchgeführt, sind bei Weitem nicht
so viele Datenbank-Verbindungen gleichzeitig vorhanden, und die maximale
Anzahl an Benutzern steigt enorm. Wenn z.B. die Client-Anwendungen nur noch
5% ihrer Laufzeit mit der Datenquelle verbunden sind, kann die Anwendung
statt 100 bis zu 2000 Log-ins verkraften. Gerade bei Web-Applikationen und
Web-Diensten (Web Services) spielt das eine große Rolle.
Auf der Client-Seite steigt durch diese Vorgehensweise
allerdings der Verwaltungsaufwand für die zu bearbeitenden Daten. Diese
müssen zwischengepuffert und zum Editieren bereit gestellt werden.
Für diese Aufgabe beinhaltet das .NET Framework die DataSet-Komponente.
Ein DataSet besteht im Wesentlichen aus einer oder
mehreren Daten-Tabellen (DataTable), die als Cache für die Ergebnismengen
der Abfragen verwendet werden. Auf diese Tabellen kann man wie gewohnt Zeilen-
und Spalten-weise zugreifen, wobei jeder Spalte ein Name, ein Datentyp und
weitere Eigenschaften zugeordnet sind. Allerdings befinden sich die Zeilen
der Tabelle alle im Hauptspeicher, so dass eine umständliche Navigation
mit einem aktuellen Datensatz und Befehlen wie First und Next entfallen.
Die Datensätze im Abfrage-Ergebnis werden direkt als nummerierte Zeilen,
Objekte der Klasse DataRow angesprochen.
Wenn das DataSet mehr als eine Tabelle enthält,
kann man zusätzlich auch Relationen und Gültigkeitsbedingungen
(constraints) definieren. Eine Relation legt eine Master-Detail-Beziehung
zwischen zwei Tabellen fest, z.B. dass die Kundennummer einer Bestellung
mit der Kundennummer eines Kunden in den Stammdaten übereinstimmen
soll. Als Gültigkeitsbedingung kann man bestimmen, dass Werte einer
bestimmten Spalte nur höchstens einmal vorkommen dürfen, oder
dass es Detail-Datensätze ohne zugehörigen Master nicht geben
darf.
Um zu demonstrieren, wie unabhängig das DataSet
tatsächlich von der Datenquelle ist, kommt das folgende Beispiel völlig
ohne Datenbank-Anbindung aus. Es erzeugt zwei Tabellen namens Kunden und
Bestellungen in einem DataSet und stellt darüber hinaus eine Reihe
von Gültigkeitsbedingungen und Beziehungen her.
- Die Spalte Kundennummer darf in der Tabelle Kunden
nur eindeutige Werte haben.
- Zu jedem Kunden gehören diejenigen Bestellungen
mit der selben Kundennummer.
- Wenn eine Kunde gelöscht wird, werden auch
alle seine Bestellungen gelöscht.
- Wenn die Kundennummer eines Kunden geändert
wird, werden die Bestellungen angepasst.
- Die Bestellnummer einer Bestellung muss innerhalb
der Tabelle eindeutig sein.
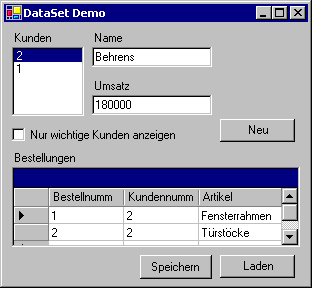
Bild 1: Auch ohne Datenquelle bildet das DataSet
eine gute Grundlage für eine Dokumenten-basierte Anwendung.
Wie die beiden Tabellen erzeugt werden, wird in Listing
1 demonstriert. Dort kann man gleich auch noch sehen, wie zwei Datensätze
in die Kunden-Tabelle eingefügt werden. Die Bedingung 5 wird als Eigenschaft
Unique der entsprechenden Spalte realisiert.
// Kunden-Tabelle erstellen
DataTable kundenTable = dataSet1.Tables.Add("Kunden");
kundenTable.Columns.Add("Kundennummer", typeof(Int32));
kundenTable.Columns.Add("Jahresumsatz", typeof(Double));
kundenTable.Columns.Add("Name", typeof(String));
// Kunden alphabetisch sortieren
dataSet1.Tables["Kunden"].DefaultView.Sort = "Name";
// Zwei Datensätze eintragen
DataRow newRow = kundenTable.NewRow();
newRow["Kundennummer"] = 1;
newRow["Jahresumsatz"] = 20000;
newRow["Name"] = "Maier";
kundenTable.Rows.Add(newRow);
newRow = kundenTable.NewRow();
newRow["Kundennummer"] = 2;
newRow["Jahresumsatz"] = 180000;
newRow["Name"] = "Behrens";
kundenTable.Rows.Add(newRow);
// Tabelle mit Bestellungen erstellen
DataTable bestellungenTable = dataSet1.Tables.Add("Bestellungen");
DataColumn newColumn = bestellungenTable.Columns.Add("Bestellnummer", typeof(Int32));
newColumn.Unique = true;
bestellungenTable.Columns.Add("Kundennummer", typeof(Int32));
bestellungenTable.Columns.Add("Artikel", typeof(String));
// Beziehung zwischen Bestellungen und Kunden herstellen
dataSet1.Relations.Add("KundenBestellungen", dataSet1.Tables["Kunden"].Columns["Kundennummer"],
dataSet1.Tables["Bestellungen"].Columns["Kundennummer"]);
Listing 1: Das DataSet enthält zwei Tabellen.
Die Master-Detail-Beziehung wird durch ein DataRelation-Objekt hergestellt.
Um die Master-Detail-Beziehung zwischen Bestellungen
und Kunden auszudrücken, wird eine Instanz der Klasse DataRelation
erzeugt und in die Eigenschaft Relations des DataSet eingehängt. Dieses
Objekt definiert eine Beziehung zwischen den Werten der Spalte Kundennummer
der Tabelle Bestellungen und den Einträgen in die gleichnamige Spalte
der Kunden-Tabelle. Nur wenn diese beiden Werte gleich sind, gehört
die Bestellung zum Kunden. Das DataRelation-Objekt kann man wie im Beispiel
entweder durch das Programm erzeugen oder in der IDE mit dem Komponenten-Designer
entwerfen.
Für die Verhaltensweise 3 und 4 ist ein Constraint-Objekt
in der Eigenschaft Constraints der Tabelle Bestellungen zuständig.
Es hat eine Eigenschaft DeleteRule und eine Eigenschaft UpdateRule, die
beide auf Cascade stehen, um den gewünschten Effekt zu erreichen. Andere
Optionen wären hier, den Detail-Datensatz unverändert zu lassen
oder seine Kundennummer auf einen vorgegebenen Wert (z.B. Null) zu setzen.
Die Eindeutigkeit der Kundennummer erreicht man durch
ein weiteres Constraint-Objekt in der Tabelle Kunden. Beide Constraint-Objekte
werden automatisch erzeugt und eingefügt, wenn man das DataRelation-Objekt
generiert.
Damit enthält die Anwendung ein vollständig
eingerichtetes DataSet mit zwei Tabellen in einer Master-Detail-Abhängigkeit
und Gültigkeitsüberprüfung. Als nächstes sollen diese
Daten im Formular dargestellt und geändert werden. Damit die Tipparbeit
beim Ändern jedoch nicht vergebens ist, besorgen die zwei kleinen Funktionen
aus Listing 2 das Sichern und Laden des DataSet-Inhalts in und aus einer
Datei. Die Datei ist ein XML-Dokument und die beiden Funktionen sind ein
kleiner Vorgeschmack auf die umfangreiche Unterstützung, die das .NET-Framework
für diesen Standard bietet. Mehr zu diesem Thema lesen Sie im dritten
Teil dieser ADO.NET-Einführung.
private void SpeichernButtonClick(object sender, System.EventArgs e)
{
dataSet1.WriteXml("c:\\kunden.xml");
}
private void LadenButtonClick(object sender, System.EventArgs e)
{
dataSet1.Clear();
dataSet1.ReadXml("c:\\kunden.xml");
}
Listing 2: So einfach wird der gesamte DataSet-Inhalt
in ein XML-Dokument geschrieben und wieder gelesen.
Daten anbinden
Jetzt kommen wir zur Ankopplung von Steuerelement
an das DataSet. Im Listing 3 wird als erstes eine Listbox über die
Eigenschaft DataSource an die Daten-Tabelle gebunden. Der Wert von DisplayName
legt die Spalte fest, die in der Listbox angezeigt wird. Wenn man sich die
Dokumentation zu Listbox.DataSource ansieht, stellt man fest, dass die Eigenschaft
vom Typ her ein einfaches object ist, d.h. man kann hier im Grunde jedes
beliebige Objekt zuordnen. Erlaubt sind allerdings nur Instanzen der Klassen
DataTable, DataSet, DataView, DataViewManager, IList und IListSource. Studiert
man diese Aufzählung etwas genauer, so stellt man fest, dass DataTable,
DataSet und DataViewManager IListSource implementieren, während DataView
von IList erbt. Nun ist IListSource wiederum eine Schnittstelle mit nur
einer Methode namens GetList, die eine IList-Referenz zurückgibt.
// Listbox an die Kundennummer anbinden
listBox1.DataSource = dataSet1.Tables["Kunden"].DefaultView;
listBox1.DisplayMember = "Kundennummer";
// Textfelder an Kundenname und Jahresumsatz anbinden
textBox1.DataBindings.Add("Text", dataSet1.Tables["Kunden"].DefaultView, "Name");
textBox2.DataBindings.Add("Text", dataSet1.Tables["Kunden"].DefaultView, "Jahresumsatz");
// Datengitter an die zum Kunden gehörigen Bestellungen anbinden
dataGrid2.DataSource = dataSet1.Tables["Kunden"].DefaultView;
dataGrid2.DataMember = "KundenBestellungen";
Listing 3: Drei unterschiedliche Arten der Daten-Anbindung
von Steuerelementen
Somit lässt sich alles auf eine Schnittstelle
zurückführen. Offensichtlich bindet die Listbox immer an ein IList-Interface.
Falls eine Datenquelle IList nicht selbst implementiert, muss sie über
IListSource zumindest eine Methode zur Verfügung stellen, die ein passendes
Objekt erzeugen kann. Die Referenz ListBox.DataSource ist deshalb nicht
vom Typ IList sondern ganz allgemein vom Typ object, um diese beiden Wege
zu ermöglichen. (Bemerkenswerterweise sind ja in .NET auch Schnittstellen
Objekte.)
Das über die ListBox gesagte gilt übrigens
auch für alle anderen Steuerelemente, die mehr als eine Zeile einer
Datenquelle darstellen können. Dazu gehören u.a. das Kombinationsfeld
(ComboBox) und das Daten-Gitter (DataGrid). Klassen, welche IList implementieren
gibt es ja eine ganze Menge, und jede von ihnen eignet sich als Datenquelle
für ein solches Steuerelement. Insbesondere erbt auch das Array von
IList und kann deshalb direkt in einer Listbox oder einem Daten-Gitter dargestellt
werden.
Zurück zur Daten-Tabelle und seiner IListSource-Implementierung.
Wie wird wohl die Liste aussehen, die eine Daten-Tabelle generieren kann?
Es handelt sich um eine Instanz von DataView, das ja selbst IList implementiert.
DataView stellt eine Sicht auf eine Daten-Tabelle dar, die eine aktuelle
Zeile kennt und gegenüber der Original-Tabelle auch eingeschränkt
sein kann. Mit DataView.RowFilter kann man einen Ausdruck definieren, den
die Zeilen der Tabelle erfüllen müssen, damit sie angezeigt werden.
Der Ausdruck ist eine Suchbedingung, ähnlich wie sie innerhalb der
WHERE-Klausel eines SQL-Befehls verwendet wird, also z.B Country = 'Germany'.
Ein anderer Filter in der Daten-Sicht ist der RowStateFilter, der nach dem
Bearbeitungszustand der Tabellen-Zeile selektiert. Hier gibt es u.a. die
Möglichkeiten Added, Deleted und ModifiedCurrent, um wahlweise die
neuen, gelöschten bzw. geänderten Zeilen anzuzeigen.
Außerdem verfügt die Daten-Sicht auch über
eine Eigenschaft Sort, mit der die angezeigten Zeilen sortiert werden können.
Man übergibt hier einen oder mehrere Spaltennamen, die durch Komma
getrennt werden und ein optionales ASC oder DESC tragen. Damit wird spezifiziert,
ob auf- oder absteigend sortiert werden soll.
Im Beispiel wird die Eigenschaft DefaultView benutzt,
um die Listbox und die Textboxen an die Tabelle zu binden. Wie der Namen
schon sagt, enthält diese Eigenschaft die standardmäßig
vorgegebene Sicht auf die Daten-Tabelle. Es ist allerdings möglich,
beliebig viele weitere Sichten hinzuzufügen. Die Verwendung der DefaultView
ist ein einfacher Weg, auf die erwähnten Darstellungs-Optionen Einfluss
zu nehmen. In Listing 1 wird für die Kunden-Tabelle eine Sortierung
nach dem Namen festgelegt und in Listing 4 ist zu sehen, wie ein an- und
abschaltbarer Filter auf die Daten-Sicht implementiert wird.
private void checkBox1_CheckedChanged(object sender, System.EventArgs e)
{
if (checkBox1.Checked)
dataSet1.Tables["Kunden"].DefaultView.RowFilter = "Jahresumsatz > 100000";
else
dataSet1.Tables["Kunden"].DefaultView.RowFilter = "";
}
Listing 4: Durch Setzen eines Filter-Ausdrucks
werden die in der Daten-Sicht angezeigten Zeilen eingeschränkt.
Die Textboxen werden mit einem im Grunde identischen
Mechanismus aber auf etwas anderem Weg an die Tabelle angebunden. Wie die
meisten Steuerelement besitzen sie mit der Eigenschaft DataBindings eine
Kollektion von Binding-Objekten, mit denen jede beliebige Eigenschaft der
Textbox aus einer Datenquelle gelesen werden kann. Die Bindung muss hier
insofern dynamisch sein, als der Anwender beim Rollen durch die Listbox
erwartet, dass die Werte in den Text-Boxen sich anpassen. Das entsprechende
Binding-Objekt wird mit der Anweisung
textBox1.DataBindings.Add("Text", dataSet1.Tables["Kunden"].DefaultView, "Name");
erzeugt. Im vorliegenden Fall verknüpft es die
Eigenschaft Text der Textbox mit dem Datenelement Name der Datenquelle dataSet1.Tables["Kunden"].DefaultView.
Die Datenquelle kann hier entweder ein beliebiges Objekt sein, das eine
Eigenschaft Name enthält oder eine Liste (d.h. eine IList-Implementierung),
deren aktuelles Objekt eine solche Eigenschaft aufweist. Die erste dieser
beiden Möglichkeiten bedeutet, dass man beispielsweise mit
textBox2.DataBindings.Add("Text", textBox1, "Text");
in textBox2 eine ständig aktualisierte Kopie
des Inhalts von textBox1 erhält. Die zweite Variante wird im Beispielprogramm
benutzt, indem die Textbox an die Default-Daten-Sicht der Tabelle gebunden
wird, die ja ihrerseits IList implementiert. Hier bestimmt die aktuelle
Position des Enumerators, welcher Wert gerade in der Textbox sichtbar ist.
Schließlich wird in Listing 3 noch das Datengitter
angebunden, damit es die jeweils verknüpften Bestellungen aus der Detail-Tabelle
anzeigt. Interessanterweise muss man hier als Datenquelle nicht die Tabelle
Bestellungen angeben, sondern die Master-Tabelle Kunden. Die Eigenschaft
DataMember wird auf KundenBestellung gesetzt, was dem Namen der DataRelation
entspricht, mit der die Master-Detail-Beziehung hergestellt wird. Im Grunde
ist das Daten-Gitter also an die Relation zwischen den beiden beteiligten
Tabellen angebunden. Würde man stattdessen die Tabelle Bestellungen
als Datenquelle wählen, wäre ein Daten-Gitter das Ergebnis, welches
ständig alle vorhandenen Bestellungen anzeigt.
Dieser Mechanismus zur Daten-Bindung an Steuerelemente
ist äußerst flexibel und erlaubt das Anbinden von Steuerelementen
an andere Steuerelemente, das Anbinden von Listboxen an arrays, das Anbinden
von Daten-Gittern an beliebige Listen und so fort. Der Nachteil, mit dem
diese Flexibilität erkauft wird, liegt in der mangelnden Typsicherheit
beim Erzeugen der Binding-Objekte. Da diese nur ein beliebiges Objekt und
eine Zeichenkette als Herkunftsort der Daten enthalten, können sie
die Gültigkeit dieser Angaben zur Übersetzungszeit nicht feststellen.
Deshalb treten durch falsche Datenbindung hervorgerufene Fehler erst zur
Laufzeit in Form von Exceptions auf.
Aktualisierung der Datenbank
Bis jetzt wurden die Daten des DataSet aus einer XML-Datei
gelesen und nach der Änderung auch wieder dorthin geschrieben. Die
andere Alternative ist, die Daten aus einer ADO.NET Datenquelle, d.h. einer
Datenbank zu holen. Wie in der ersten Folge beschrieben, benötigt man
dazu einen DataAdapter für die gewünschte Datenquelle,
also zum Beispiel einen OleDbDataAdapter. Der Daten-Adapter greift über
eine Datenbankverbindung, ein OleDbConnection-Objekt auf die Datenquelle
zu und generiert die Ergebnismenge mit einem SQL-Befehl in Form einer Instanz
von OleDbCommand. Die ermittelten Daten füllen über die Methode
OleDbDataAdapter.Fill eine Daten-Tabelle innerhalb eines DataSet.
Als Beispiel greifen wir auf die Tabelle Customer der Nordwind-Datenbank
zu, um eine Kunden-Tabelle im DataSet zu füllen.
Schwieriger als die Abfrage ist allerdings in vielen
Fällen die Aktualisierung der Datenquelle. Hier leistet das DataSet
Vorarbeit, indem es für alle Zeilen in den Tabellen sowohl die Original-Werte
sichert, wie sie aus der Datenbank gekommen sind, als auch einen Status
mitführt, der aussagt, ob die Zeile geändert, gelöscht oder
neu eingefügt wurde. Der Daten-Adapter verfügt auch über
eine Methode Update, in der er für jede veränderte Zeile der Daten-Tabelle
je nach Art der Änderung ein UPDATE, INSERT oder DELETE-Statement aufruft.
Auf den Aufbau dieser Statements kommt es nun an. Je nach Anwendungsfall
werden sie von einem Assistenten in der IDE, einem CommandBuilder-Objekt
oder per Hand zusammengestellt.
Betrachten wir einen einfachen Fall und ziehen den
OleDbDataAdapter auf ein (neues) Formular. Sofort öffnet sich
der Konfigurations-Assistent zum Erzeugen einer Datenbank-Verbindung und
dem anschließenden Generieren einer Abfrage. Die Datenbank-Verbindung
soll als Provider auf die Jet-Engine zugreifen, als Datenbank wählen
wir nwind.mdb, das sich (in der Beta 2) unter Common7/Tools/Bin
verbirgt. Die Abfrage kann man entweder bequem mit dem Generator erstellen
oder einfach eintippen. Sie soll
SELECT CustomerID, CompanyName, Country FROM Customers
lauten.
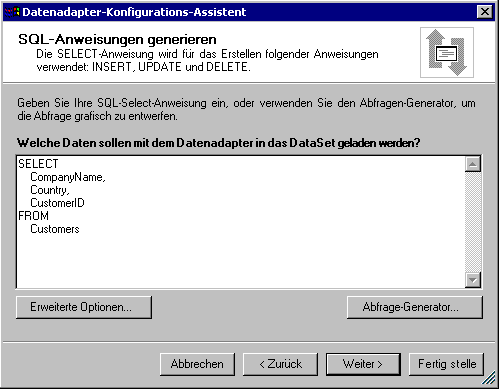
Bild 2: Der Konfigurations-Assistant für
den Daten-Adapter generiert die SQL-Befehle zur Aktualisierung der Datenquelle
automatisch.
Wenn man nun den fertig konfigurierten Daten-Adapter
untersucht, findet man nicht nur die zu erwartende SelectCommand-Eigenschaft,
sondern auch Einträge für DeleteCommand, InsertCommand
und UpdateCommand. Der Text für das DeleteCommand
lautet:
DELETE FROM Customers WHERE (CustomerID = ?) AND (CompanyName = ?) AND (Country = ?)
Die Fragezeichen stehen für Parameter-Werte,
da der OleDb Managed Provider keine benannten Parameter beherrscht. Die
Werte werden einfach in der Reihenfolge ihres Auftretens für die Platzhalter
eingetragen. Auch die Parameter hat der Konfigurations-Assistent erzeugt,
sie können in der Eigenschaft Parameters eingesehen werden:
| Parameter-Name |
Quell-Spalte |
Version |
| CustomerID |
CustomerID |
Original |
| CompanyName |
CompanyName |
Original |
| Country |
Country |
Original |
Beim Ausführen dieses Statements werden die Parameter-Werte
also aus der aktuellen Zeile der Daten-Tabelle geholt. Natürlich handelt
es sich nicht um die aktuellen Werte, die Zeile wurde ja aus der Daten-Tabelle
gelöscht, sondern um die Original-Werte, wie sie ursprünglich
aus der Datenbank gelesen wurden. Wenn dieses Statement für jede gelöschte
Zeile einmal aufgerufen wird, ist die Datenbank aktualisiert.
Wer die Nordwind-Datenbank kennt und weiß, dass
CustomerID ein Primärschlüssel und damit eindeutig ist,
wundert sich vielleicht, warum alle drei Spalten und nicht nur die erste
zur Identifizierung des zu löschenden Datensatzes ausgewertet werden.
Im Grunde würde die CustomerID alleine natürlich genügen,
allerdings können Konflikte bei parallelen Änderungen dann nicht
erkannt werden. ADO.NET arbeitet ja mit unverbundenen Datenmengen und dadurch
zwangsweise mit optimistischem Locking, was ja eigentlich bedeutet: Ohne
Locking. Zwei Anwendungen können die selbe Ergebnismenge abholen und
dann vollkommen unabhängig voneinander bearbeiten. Nehmen wir nun an,
die erste Anwendung ändert das Feld Country des Kunden mit
der CustomerID 2, während die zweite Anwendung genau diesen
Kunden löscht.
Wir haben die genaue Form des UPDATE -Statements noch
nicht betrachtet, verlassen uns aber für den Moment darauf, dass es
tatsächlich den alten Wert in der Datenbank durch den neuen ersetzt.
Was passiert nun, wenn das DELETE-Kommando nach dem UPDATE-Kommando ausgeführt
wird? Wenn die WHERE-Klausel nur die CustomerID enthält, wird
der soeben geänderte Datensatz gelöscht, obwohl die löschende
Anwendung von einem anderen Wert im Feld Country ausging. Dies
ist unter Umständen ein Fehler, z.B. wenn der Anwender alle italienischen
Kunden entfernen wollte. In der Version, wie sie der Konfigurations-Assistent
tatsächlich generiert, findet das DELETE-Statement den zu löschenden
Datensatz nicht und kann einen Konflikt melden. Es ist dann allerdings Aufgabe
des Anwendungs-Programms, das Problem dem Anwender zu berichten und den
Konflikt geeignet zu lösen.
Analog zum DELETE-Kommando enthält auch der UPDATE-Befehl
eine WHERE-Klausel über alle abgefragten Feldwerte:
UPDATE Customers SET CompanyName = ?, CustomerID = ?, Country = ?
WHERE (CustomerID = ?) AND (CompanyName = ?) AND (Country = ?)
Im Gegensatz zum DELETE-Statement benötigt es
aber sowohl die alten als auch die neuen Feldwerte und besitzt dementsprechend
eine doppelte Parameterliste:
| Parameter-Name |
Quell-Spalte |
Version |
| CustomerID |
CustomerID |
Current |
| CompanyName |
Companyname |
Current |
| Country |
Country |
Current |
| Original_CustomerID |
CustomerID |
Original |
| Original_CompanyName |
CompanyName |
Original |
| Original_Country |
Country |
Original |
| Select_CustomerID |
CustomerID |
Current |
Der letzte Parameter wird für die zweite Anweisung
im UpdateStatement benötigt. Mit
SELECT CompanyName, CustomerID, Country FROM Customers WHERE (CustomerID = ?)
wird nach dem Einfügen des Datensatzes in die
Datenbank derselbe Datensatz neu geholt, um den Inhalt des DataSets aufzufrischen.
Es wäre ja möglich, dass er durch einen Trigger beim Einfügen
geändert wird.
Die vom Konfigurations-Assistenten erstellte INSERT-Anweisung
lautet
INSERT INTO Customers (CompanyName, CustomerID, Country) VALUE (?, ?, ?)
und dementsprechend sind die Parameter:
| Parameter-Name |
Quell-Spalte |
Version |
| CompanyName |
CompanyName |
Current |
| CustomerID |
CustomerID |
Current |
| Country |
Country |
Current |
| Select2_CustomerID |
CustomerID |
Current |
Auch hier bezieht sich der letzte Parameter auf den
zweiten Befehl, der bei jedem neuen Datensatz ausgeführt wird und die
Zeile im DataSet aktualisiert:
SELECT CompanyName, CustomerID, Country FROM Customers WHERE (CustomerID = ?)
Somit übernimmt der Konfigurations-Assistent
in einfachen Fällen die Aufgabe, die korrekten Aktualisierungs-Statements
für eine gegebene Abfrage zu erzeugen. Falls der Daten-Adapter nicht
mit dem Assistent konfiguriert, sondern zur Laufzeit erzeugt wird oder zur
Laufzeit ein anderes SQL-Statement zugewiesen bekommt, kann man auch auf
einen CommandBuilder zurückgreifen. Dieser wird einfach nur erstellt
und dem Daten-Adapter zugewiesen:
new OleDbCommandBuilder(oleDbDataAdapter1);
Der CommandBuilder generiert dann die drei SQL-Befehle
für die Aktualisierung im Adapter, soweit diese nicht schon vorgegeben
sind. Falls das SQL-Statement erst nachträglich formuliert oder geändert
wird, muss man den CommandBuilder mit UpdateSchema zum
Auffrischen der erstellten Kommandos auffordern.
Die automatische Generierung von UPDATE, DELETE und
INSERT-Anweisungen hat aber ihre Grenzen, sobald die Abfrage mehr als eine
Tabelle umfasst. Das ist auch verständlich, wie folgender Anwendungsfall
zeigt:
SELECT Customers.Country, Orders.OrderID FROM Customers, Orders
WHERE Customers.CustomerID = Orders.CustomerID
Wie soll diese Datenmenge gegen die Datenbank aktualisiert
werden, wenn in der ersten Spalte eine Landesbezeichnung geändert wird?
Soll das Land für diesen Kunden entsprechend aktualisiert werden, so
dass auch die anderen Bestellungen dieses Kunden auf das neue Land lauten?
Oder soll etwa ein neuer Kunde mit gleichem Namen und anderer Länderbezeichnung
angelegt werden? Welche Kundennummer erhält er dann? In solchen und ähnlichen
Fällen bleibt dem Entwickler nur, eigene Aktualisierungs-Befehle zu
formulieren, soweit dies von der Geschäfts-Logik her möglich ist.
Für Anhänger des pessimistischen Lockings
wie der Autor einer ist, sind die Auskünfte der ADO.NET-Dokumentation
wenig befriedigend. Falls man mit pessimistischem Locking arbeiten möchte,
soll man auf das gute alte ADO (sprich auf COM, runtime callable wrappers
und unmanaged code) zurückgreifen. Wenn auch einzusehen ist, dass optimistisches
Locking die Performanz und Skalierbarkeit einer Anwendung deutlich verbessert,
so ist pessimistisches Locking doch die weitaus bequemere Variante (Einen
Konflikt verhindern ist besser als ihn zu lösen, wenn er schon aufgetreten
ist) und in manchen Fällen, wie zum Beispiel bei Buchungssystemen auch
schlichtweg notwendig. Hier müssen wir wohl auf ADO.NET 2 hoffen.
Typisiserte DataSets
Dieser Überblick über ADO.NET DataSets und
Daten-Bindung wäre nicht vollständig ohne zumindest kurz auf typisierte
DataSets einzugehen. Diese gehen im Grunde nicht über die bisher beschriebenen
Möglichkeiten hinaus, führen aber zu wesentlich sichererem und
lesbarerem Code.
Ein typisiertes DataSet besteht aus Tabellen, die
anders als normale Daten-Tabellen nicht aus allgemeinen Objekten sondern
aus spezifischen Instanzen passend zur betrachteten Ergebnismenge bestehen.
Das typisierte DataSet zum vorherigen Beispiel besitzt eine Eigenschaft
Customers, die eine Tabelle der Klasse CustomersDataTable
enthält. Die Zeilen dieser spezielle Daten-Tabelle wiederum sind keine
normalen DataRows sondern davon abgeleitete CustomersRows,
welche Eigenschaften wie CompanyName und CustomerID aufweisen.
Mit typisierten DataSets kann das Anwendungsprogramm also typsicher über
Eigenschaften auf die Tabellen, Spalten und Werte zugreifen statt über
Strings. Damit wird der Quellcode nicht nur wesentlich lesefreundlicher,
viele Fehler wie zum Beispiel ein falscher Spaltenname treten auch schon
beim Übersetzen auf statt wie im untypisierten DataSet zur Laufzeit.
Typisierte DataSets kann man als Entwickler entweder
selbst definieren oder von der Entwicklungsumgebung generieren lassen. In
beiden Fällen entstehen von DataSet, DataTable und
DataRow abgeleitete Klassen, welche die zusätzlichen Eigenschaften
enthalten. Leider beschränkt die Entwicklungsumgebung ihre Unterstützung
derzeit auf DataSets, die mit Daten-Adapatern verknüpft sind, so dass
unabhängige und XML-basierte DataSets außen vor bleiben. Die
Vorgehensweise ist jedoch denkbar einfach. Sobald mindestens ein DataAdapter
im Formular vorhanden ist, kann man entweder über das Hauptmenü
mit Daten/DataSet generieren oder über das Eigenschaftsfeld
des Daten-Adapters ebenfalls mit DataSet generieren ein Dialogfeld öffnen.
Dort gibt man als Quelle der typisierten Daten-Tabelle den Daten-Adapter
an. Visual Studio.NET generiert dann den nötigen Code innerhalb der
vorhandenen Quellcode-Datei.
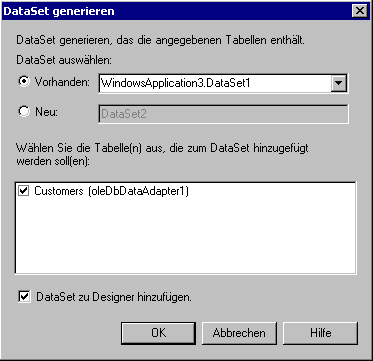
Bild 3: Der Quellcode für ein typisiertes
DataSet wird von der Visual Studio.NET IDE generiert.
Gesamtschau
ADO.NET bringt keine umwälzenden Neuerungen für
die Programmierung von Datenbank-Anwendungen. Es führt jedoch mit der
DataSet-Komponente vorhandene Konzepte wie Client-seitiges Caching und optimistisches
Locking fort und baut sie aus. Auf der anderen Seite steht die völlige
Abkehr von Prinzipien wie Server-seitigen Cursors. Dies dürfte für
nicht wenige Entwickler einen bedeutsamen Umlern-Aufwand bedeuten, der dann
allerdings mit erhöhter Skalierbarkeit der Anwendung belohnt wird.
Auch die Daten-Anbindung von Steuerelementen ist so flexibel und allgemein
gelöst wie noch nie. Wünschenswert wäre allerdings eine Option
zur Unterstützung von pessimistischem Locking und die Möglichkeit,
ein typisiertes DataSet ohne Daten-Adapter zu konfigurieren.
Der dritte und letzte Teile dieser Einführung
handelt von der umfangreichen XML-Unterstützung in ADO.NET, die in
dieser Folge nur angedeutet wurde.
Den Quellcode zu diesem Artikel
können Sie hier downloaden.
Peter Pohmann, 37, ist Geschäftsführer
von pohmann & partner, einem Softwarehaus in Niederbayern. Er ist seit über
15 Jahren als Entwickler, Fachautor, Coach, Referent und Berater für
Objektorientierte Technologien und Windows-Programmierung tätig. Er
freut sich über Feedback zu diesem und verwandten Themen an peterDOTpohmannADDdataweb.de
|

